
IA en Calsots.com: Mi Apuesta por la Innovación
Desde que salió ChatGPT he estado explorando formas de integrar la inteligencia artificial en el comercio electrónico, y hoy quiero […]
Desde que salió ChatGPT he estado explorando formas de integrar la inteligencia artificial en el comercio electrónico, y hoy quiero […]

En un mundo en rápido movimiento, el término «Tokenización de activos» está ganando un gran reconocimiento. ¿Pero qué significa realmente?
Cómo empezar a programar en Solidity En una reciente charla en Vic, me encontré rodeado de entusiastas digitales que me

Loyalty Program, un Smart Contract en Solidity que sirve como base para implementar un programa de fidelización en blockchain.
Uno de los conceptos más intrigantes de la blockchain es el «Contrato Inteligente» o «Smart Contract». Pero, ¿qué es un contrato inteligente y cómo funciona?

El término «blockchain» se ha convertido en una palabra de moda en la tecnología, las finanzas y otros sectores. Pero, ¿qué es Blockchain exactamente y por qué es tan revolucionario?
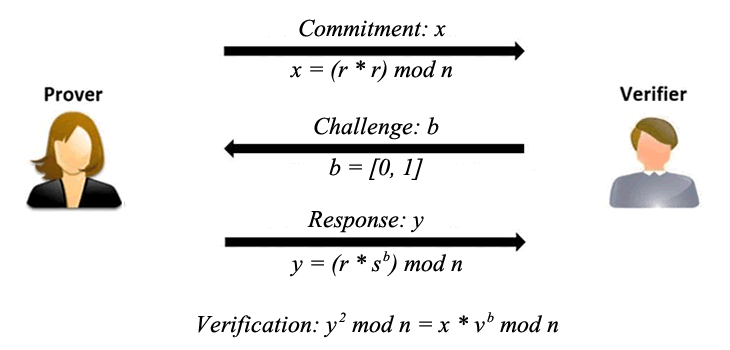
Es un verdadero placer (y también un motivo de orgullo) compartir un desarrollo del algoritmo Fiat-Shamir para las Zero Knowledge

En el mundo en constante evolución de la tecnología blockchain, los contratos inteligentes están desempeñando un papel cada vez más
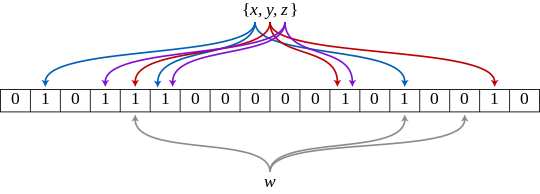
Un filtro Bloom es una estructura de datos probabilísticos que se utiliza para comprobar si un elemento es miembro de un conjunto. En esta estructura, los elementos se pueden agregar al conjunto, pero no eliminar.
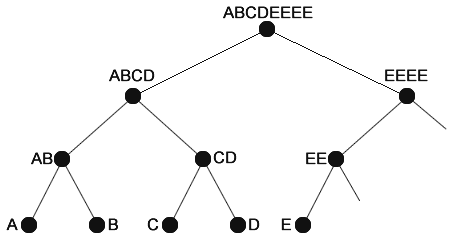
En esta entrada voy a hablar de una implementación en PHP de un «Merkle Tree«, un árbol de Merkle, una